
Classification of music is a very important and heavily researched task in the field of NLP. Previous research in this field has focused on classifying music based on mood, genre, annotations, and artist. All the approaches either used audio features, lyric as text or both in combination.
Genre classification by lyrics is itself a clear Natural Language Processing problem. The end goal of NLP is to extract some sort of meaning from text. For music genre classification, this equates to finding features to classify music using lyrics. There are a wide range of scholarly and commercial applications for automated music genre classifiers. For example, classifiers could be used to automatically analyze and sort music into large databases. Music recommendation systems could be used to automatically analyze a user’s liking’s and recommend appropriate songs to listen. Music classifier can be used to recommend music based on the mood of users. Similarity analysis which is a part of music
Data
-
We scrapped songs data from songsLyrics.com, and metrolyrics.com. Also, we used a song dataset from kaggle.com.
-
Our data included around 390,000 songs. Our data includes attributes like song, lyrics, year, artist, and a target attribute genre. For our task, we sampled 20,000 songs of each genre from our original dataset.
Pre-Processing
- Removed instances with genres like “not available” and “other”,
- Removed genres which didn’t have many instances.
- Removed unnecessary characters using regular expression.
- Removed stopwords using nltk’s english stopwords and stanford’s stopwords list.
- We stemmed tokens in each song using nltk’s Snowball stemmer.
- Some songs in our dataset had a non-english words. Using ftfy, we have fixed the
- encoding of the text, and also we removed instances which had a non-english words even after we fixed the encodings.
- We removed word such as ‘Chorus’ and ‘Verse’ which represent different parts of a song.

Target variable
For our classification task we selected 4 target variables which are the genres. Target variables are as follows:
- Classical
- Pop
- Metal
- Jazz
Features
- Similarity with four genres: We calculated the top 30 words in each genre using tf-idf. We created four different features named metal_similarity, pop_similarity, rock_simliarity, and hip_hop_similarity. If a token appeared in any of the top-30 words of any genre we used its tf-idf value to calculate the cosine similarity with the tf-idf value of that token in a particular genre in which it appeared.
- Pos tags: Using nltk tokenizer, get used a normalized count of pos tags.
- Word2vec: We trained a word2vec model on the whole dataset, and brown corpus. After training word2vec model, we used it to generate word2vec vector of each token in each song.



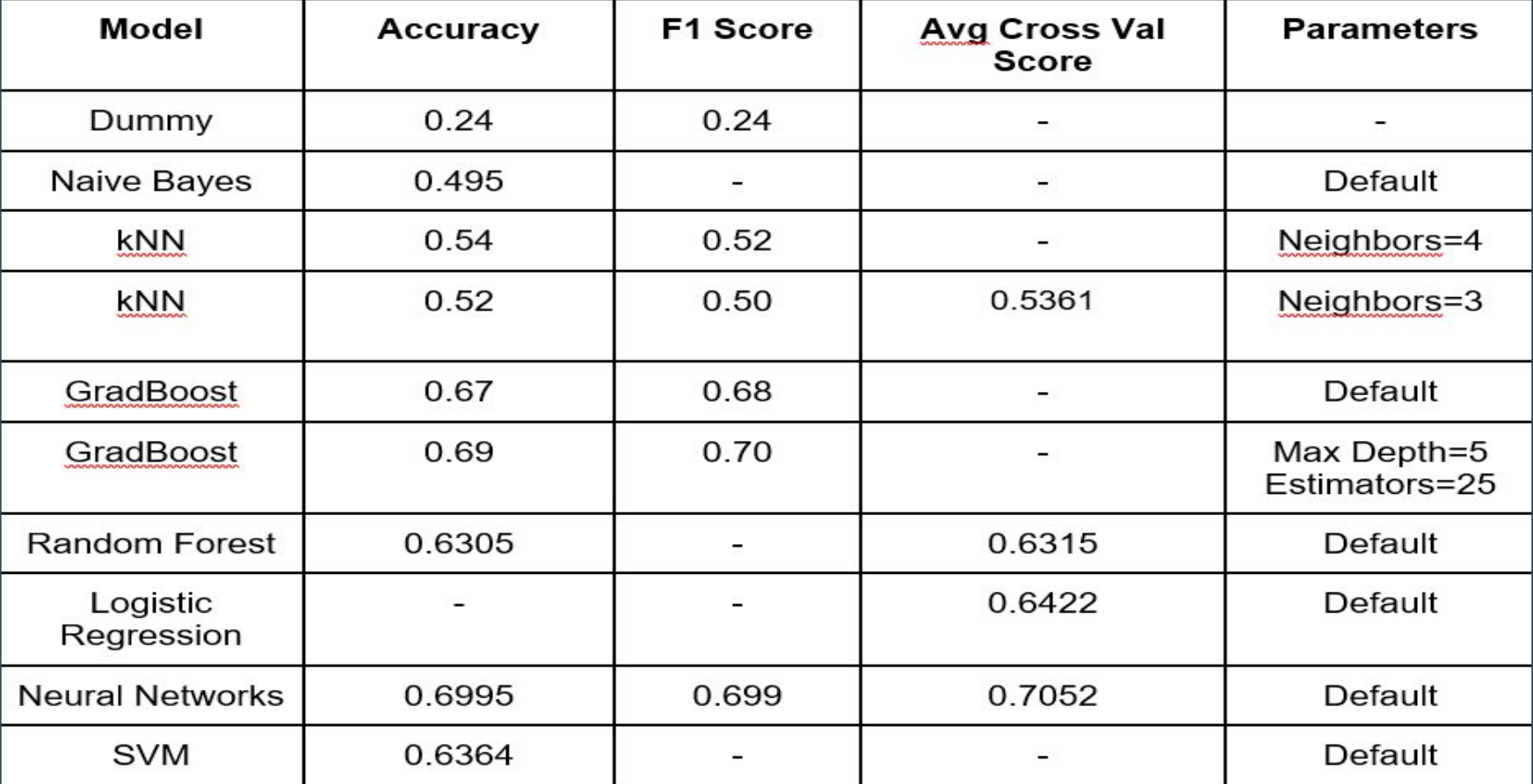
Models used:
- Dummy Classifier
- kNN CLassifier
- MLP Classifier
- Gradient Boosting
- Logistic Regression
Metrics Used:
- Accuracy
- F1 Score
Conclusion
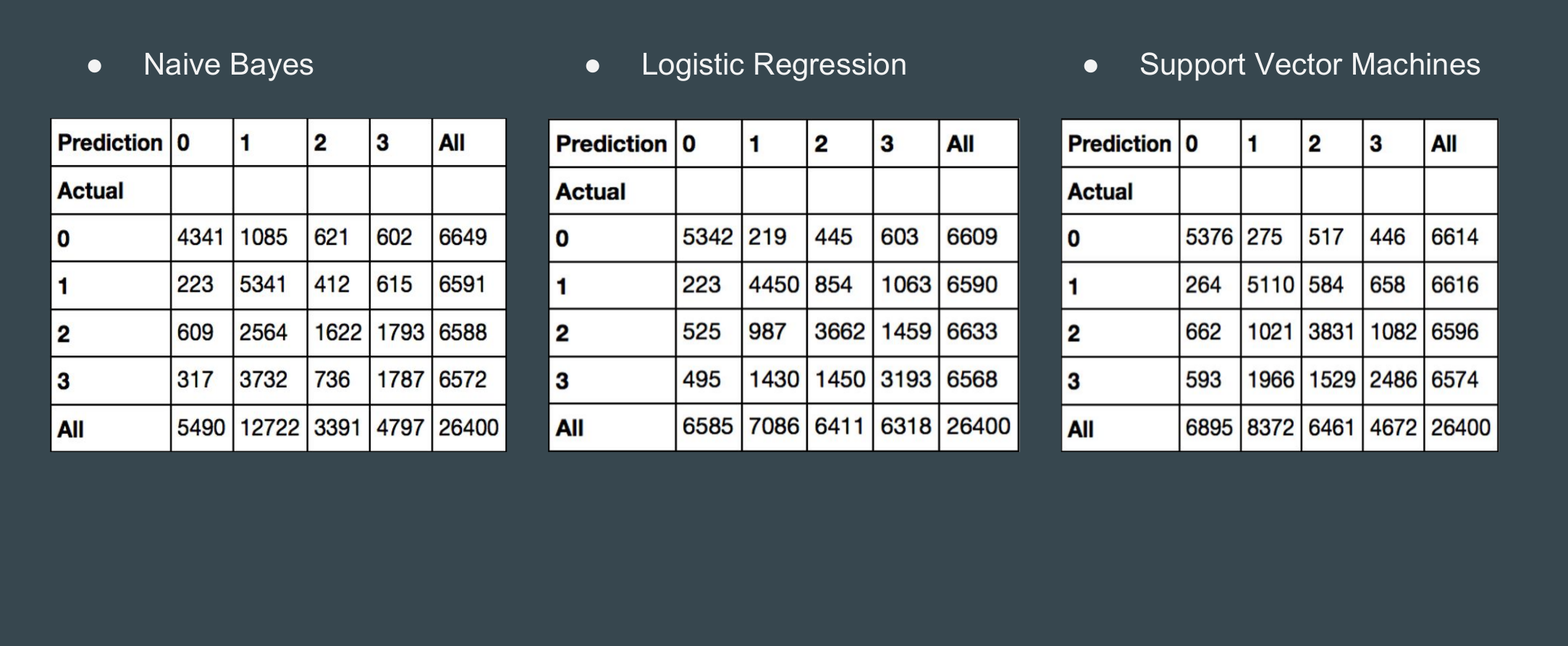
After analysis of tf-idf values and confusion matrix we came to know how similar rock and metal songs are. Most of the Classifiers were also predicting wrong labels among these two genres. For the future work, we can use some more features such as parse trees, word endings, and length of a song to distinguish between these two genres and further increase accuracy of different classifiers.
- Results:
- Confusion Matrices:
[Project Link] (https://github.com/kartikprakash1993/Lyrics-Analysis)
