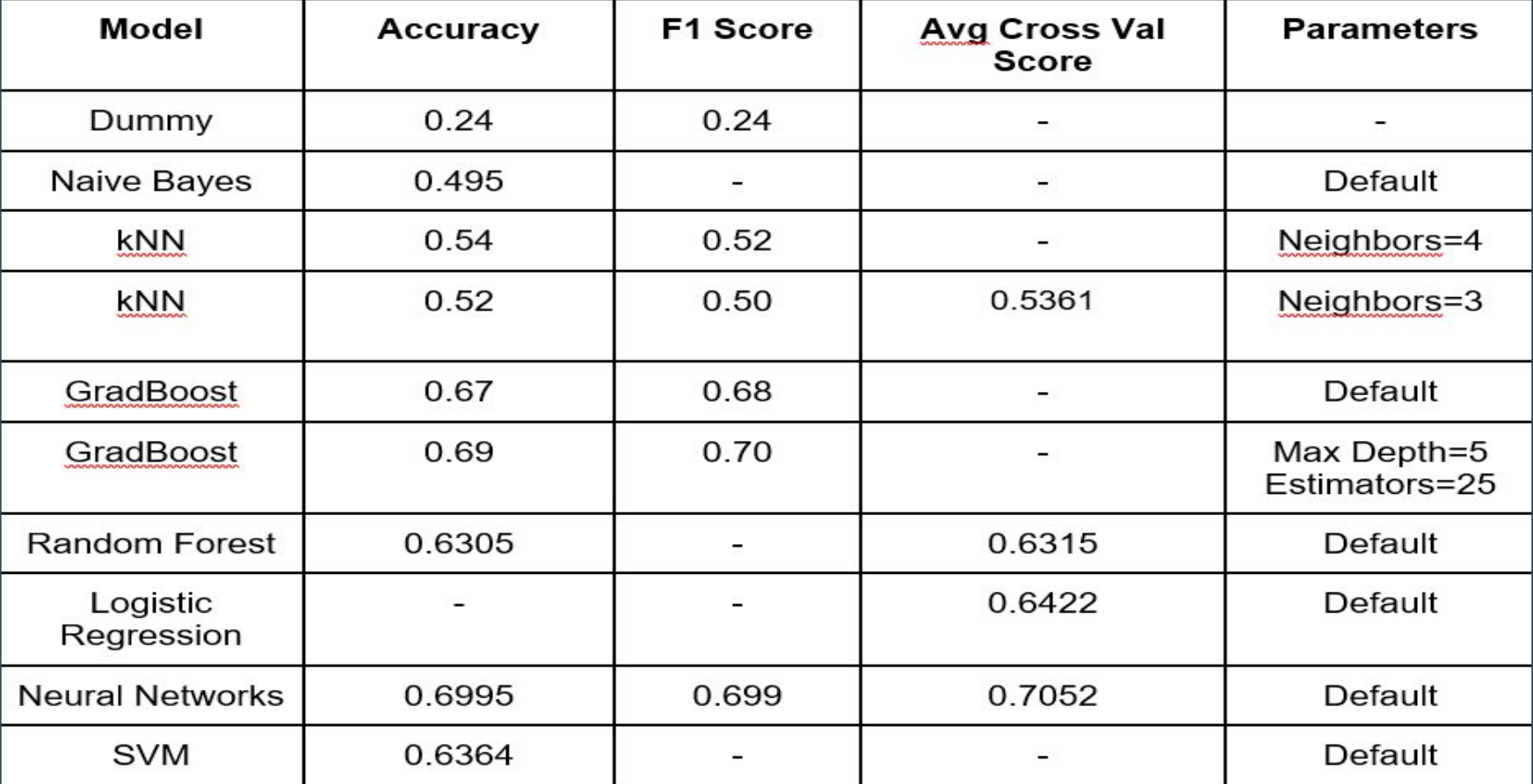
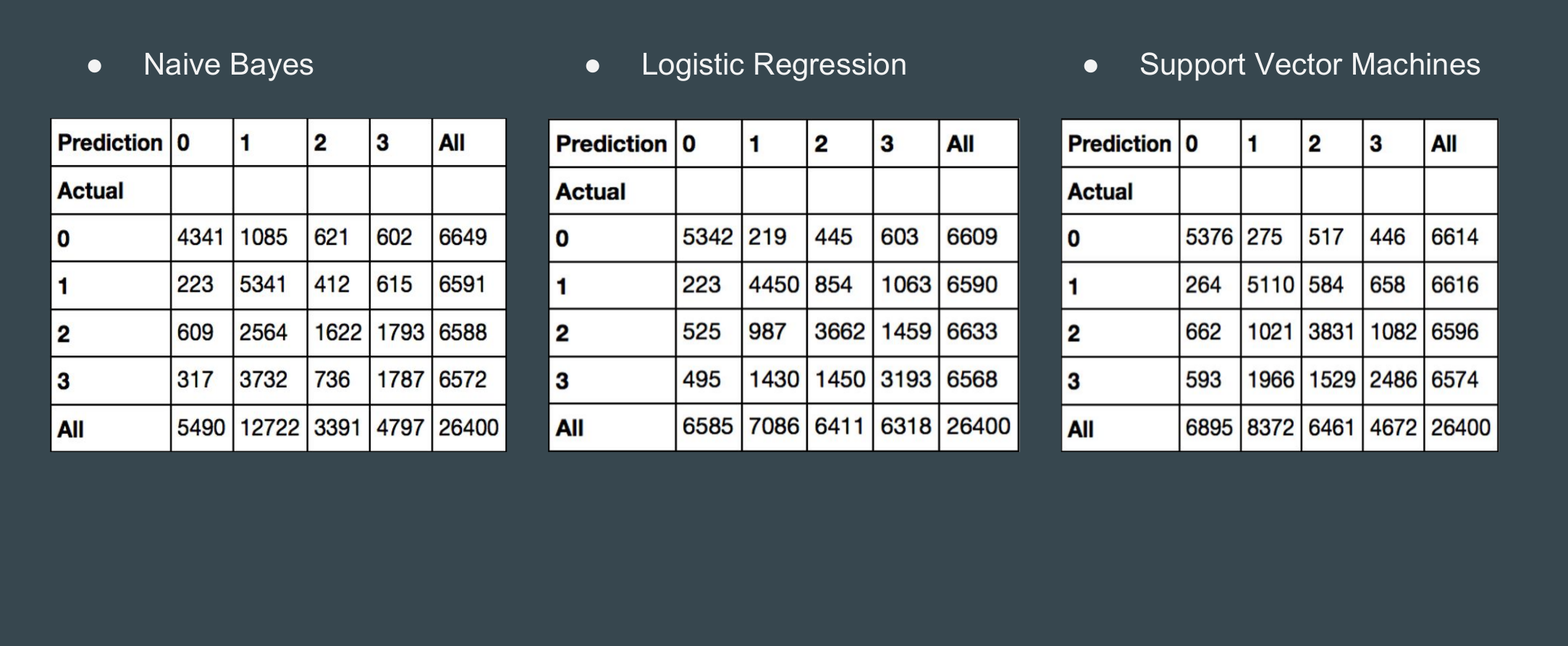
COVID-19 Contract tracing is an application for an Android phone which notifies a user if they have come in contact with someone who reported COVID-19 symptoms or a test result.
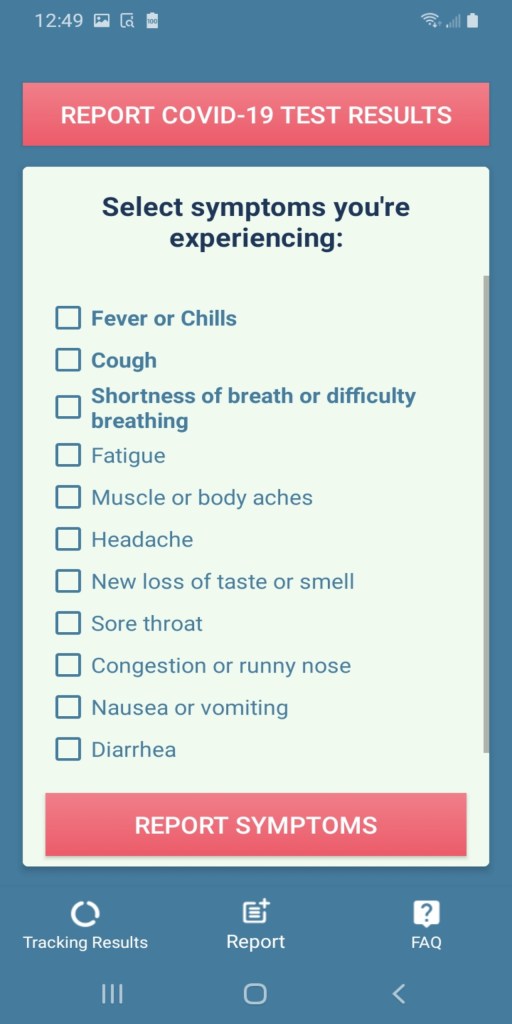

According to Google’s play store policy and current on going situation they are not approving any applications that are related to COVID-19 until and unless they are affiliated or associated with any government health organization so you won’t be able to find this application on the store but here is a link for the beta test application:
https://appdistribution.firebase.dev/i/D2oxMUWN
This app basically works around the DP-3T protocol and use’s a phones Bluetooth to communicate with nearby users. Each phone running this app will generate a unique random key every 24 hours and share that key with the other phone which is in a close proximity.
For example and for ease of understanding we will be using one user as A and some other user as B
A and B both will generate a unique key every 24 hours. If A and B comes close to each other their phone will broadcast that day’s key for each other and both the users will save that key on their respective phone within a private secure database.
After few days (<14) suppose A reports that he/she have tested positive for COVID-19, then their phone will upload that result with their past 14 days keys, now B’s phone will periodically sync with server for latest data and it will get a notification saying you came in contact with someone who tested positive within last 14 days.
User A’s phone will keep uploading that result with new key generated from that day onward until the user reports that (s)he tested negative.